
Dans les systèmes d’information modernes, la donnée est partout. Elle circule, alimente les processus métier, soutient les décisions et structure les applications. Mais pour qu’elle ait de la valeur, encore faut-il qu’elle soit bien organisée.
C’est là qu’intervient la modélisation des données. Que ce soit pour développer un logiciel, concevoir une application mobile ou construire un data warehouse, modéliser correctement ses données est une étape clé. C’est ce qui permet de transformer des besoins métiers complexes en un système d’information fiable, évolutif et durable.
Dans ce guide, on va voir comment modéliser une base de données efficacement. On parlera des types de modèles, des bonnes pratiques, des outils à connaître et des erreurs à éviter. L’idée, c’est de poser les bons fondements pour que vos projets data et applicatifs reposent sur une base solide, bien pensée… et bien modélisée.
Qu’est-ce que la modélisation des données ?
La modélisation des données, c’est l’art de représenter de façon structurée et cohérente les éléments de données d’un système d’information. C’est un processus de conception qui permet de transformer un besoin métier en une structure logique capable de stocker, organiser et exploiter l’information de manière fiable.
Autrement dit, on ne se contente pas de stocker des données, on les organise selon des relations claires, des règles précises et des objectifs bien définis. L’idée, c’est de bâtir une représentation visuelle fidèle de la réalité métier, que ce soit sous forme de diagramme, de cartographie ou de schéma formel.

Pourquoi la modélisation de base de données est cruciale pour un projet IT ?
Dans tout projet IT, la modélisation des données constitue un socle structurant. C’est elle qui permet de traduire des besoins métiers complexes en une architecture claire, cohérente et pérenne. Une modélisation bien pensée permet d’anticiper les évolutions, de garantir l’intégrité des données, de faciliter les interconnexions et d’assurer une meilleure conception de l’ensemble. À l’inverse, une modélisation absente ou mal construite génère rapidement des incohérences, des problèmes de performance, et finit par freiner l’évolution du produit.
Contrairement aux idées reçues, la modélisation ne concerne pas uniquement les bases relationnelles. Elle intervient dans de nombreux cas, comme l’intégration d’API, la gestion de référentiels métiers, la structuration de data warehouses ou encore la conception de systèmes distribués. Elle s’impose comme un levier de simplification et de cohérence dans un environnement technique de plus en plus complexe.
Modéliser, c’est aussi mieux documenter, mieux collaborer et mieux gouverner ses données. On gagne en clarté, en fiabilité et en efficacité opérationnelle. Dans une organisation data-driven, cette capacité à structurer intelligemment l’information devient un vrai facteur de compétitivité. Mieux la donnée est pensée, mieux elle est exploitée.
Quels sont les types de modèles de données ?
Tout l’enjeu, c’est de choisir le bon niveau d’abstraction. Le plus courant, c’est le triptyque classique : modèle conceptuel, modèle logique, modèle physique.
Le modèle conceptuel
Il décrit les grandes entités métier, leurs attributs et leurs associations, sans se soucier des contraintes techniques. Il sert à cadrer la vision métier de manière claire.
Le modèle logique
Il structure les données selon un formalisme (souvent modèle relationnel). On parle de tables, de clés, de types de relations. Il est indépendant du système choisi, mais il respecte les règles des bases relationnelles.
Le modèle physique
Lui, traduit tout cela dans un langage exécutable adapté à un SGBD donné. C’est là qu’on configure les index, les partitions, les performances, en tenant compte de la réalité technique.
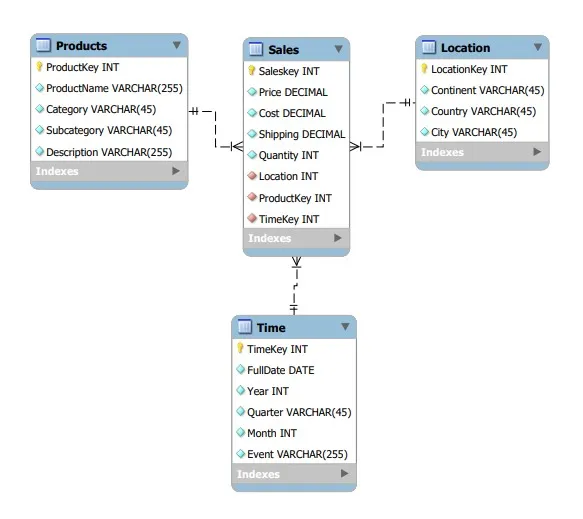
Dans un contexte analytique, on utilise aussi des modèles spécialisés comme le modèle dimensionnel, et en particulier le modèle en étoile. Cette approche dimensionnelle est pensée pour la BI. On y structure les données autour d’une table de faits centrale, reliée à des dimensions (temps, produit, client…), pour faciliter l’analyse à grande échelle.
Quels sont les outils de modélisation des données ?
Une bonne modélisation passe aussi par un bon outil. Le choix dépendra de votre contexte, de votre maturité data, et du type de projet.
Voici un tour d’horizon des meilleurs outils à connaître :
- Erwin Data Modeler : une référence du marché pour la modélisation relationnelle. Complet, robuste, adapté aux projets d’entreprise à grande échelle.
- Microsoft Visio : simple et largement utilisé pour réaliser des schémas conceptuels ou documenter une structure existante. Moins technique, mais efficace en cadrage.
- Lucidchart : outil en ligne très intuitif pour concevoir des modèles visuels. Parfait pour une utilisation collaborative ou en phase de design.
- dbt (data build tool) : incontournable dans les environnements data warehouse. Il permet de créer des modèles analytiques directement dans le code SQL.
- Outils open source (DBDesigner, Archi…) : pratiques pour démarrer ou prototyper sans frais, mais souvent limités sur les projets complexes.
Chacun a ses fonctionnalités propres. Quel que soit l’outil, l’essentiel est de pouvoir représenter, faire évoluer et partager la structure de vos données en toute transparence.
Comment modéliser une base de données ? Nos bonnes pratiques
Modéliser une base de données, c’est un travail de conception, d’analyse, de choix techniques… bref, un vrai processus structurant qui demande méthode et bon sens. Voici nos conseils pour poser les bases d’un modèle solide, efficace et pérenne.
Les différents types de bases de données
Avant même de modéliser, encore faut-il savoir sur quel type de base on travaille. Et aujourd’hui, le choix est vaste. On distingue principalement :
Les bases de données relationnelles
Le modèle classique, basé sur des tables, des relations et des clés. Il reste la norme pour les systèmes transactionnels, les applications métiers ou les référentiels bien structurés.
Les bases NoSQL
Adaptées aux données semi-structurées ou non structurées. On y retrouve plusieurs sous-familles : les bases documentaires (MongoDB), orientées colonnes (Cassandra), orientées graphe (Neo4j)… Leur modélisation suit d’autres logiques, moins normalisées.
Les bases orientées objet
Elles stockent les données sous forme d’objets, comme en programmation orientée objet. Plus rares, elles peuvent s’avérer utiles dans certains cas complexes.
Les bases analytiques ou en cloud
Pensées pour l’analyse à grande échelle (BigQuery, Snowflake…), elles nécessitent des modèles optimisés pour les lectures intensives, avec souvent une modélisation dimensionnelle.
Comment choisir la bonne base de données en fonction de son besoin ?
Il n’existe pas de base de données universelle. Le bon choix dépend toujours du contexte métier, de la nature des données, et des contraintes techniques du projet. Le bon réflexe, c’est de partir des usages avant de parler technologie.
| Contexte d’usage | Type de base recommandé | Exemples | Pourquoi ce choix |
| Projet applicatif structuré avec règles précises | Base relationnelle | PostgreSQL, MySQL, Oracle | Robuste, fiable, compatible avec les standards du marché |
| Services flexibles, données non standardisées | Base NoSQL | MongoDB, DynamoDB | Schéma souple, facile à faire évoluer, gestion des volumes hétérogènes |
| Analytique, BI, data warehouse | Base analytique / cloud data warehouse | BigQuery, Snowflake, Redshift | Optimisé pour l’exploration, l’agrégation et le machine learning |
| Cas d’usage spécifiques (graphes, moteurs de recommandation…) | Base spécialisée | Neo4j, OrientDB | Pensé pour les graphes, les objets complexes ou les moteurs métiers |
Mais au-delà des usages, le choix doit aussi s’inscrire dans l’écosystème technique global :
Est-ce que la base s’intègre bien au système d’information existant ? Est-ce que l’équipe d’infra pourra en assurer la maintenance, la supervision, les sauvegardes ? Est-ce que le socle est aligné avec les compétences de l’équipe de développement ?
Aujourd’hui, les ORM et les couches d’abstraction permettent de réduire l’impact technique direct du choix de base sur le code. Les vrais problèmes de performance viennent souvent moins du moteur que de la manière dont les données sont modélisées et exploitées.
En résumé : on ne choisit pas une base par effet de mode, mais parce qu’elle répond au bon besoin fonctionnel, au bon niveau de complexité, et au bon contexte d’usage.
Nos conseils pour modéliser correctement ses données
Une bonne modélisation repose autant sur la méthode que sur la posture. Voici nos recommandations pour poser les bonnes bases dès le départ.
Commencer par le concept, toujours.
Le modèle conceptuel est la première pierre de toute architecture data solide. Il permet de cartographier les entités, leurs attributs, les relations clés et les règles métiers, sans se soucier encore du stockage ou des performances. C’est une représentation partagée, lisible par les équipes métier comme techniques. Sauter cette étape, c’est prendre le risque de concevoir une base mal alignée avec les besoins réels.
Penser le modèle comme un objet vivant.
Un modèle efficace doit pouvoir évoluer sans tout casser. Il faut penser en couches, documenter chaque étape, anticiper les dépendances, et garder une approche modulaire. La structure de la base doit pouvoir suivre les évolutions du produit, les changements d’organisation ou les migrations technologiques.
Valider la logique avant la mise en œuvre.
Le modèle logique (souvent de type relationnel) permet de transformer les concepts métier en tables, clés, types de données et contraintes. C’est le moment de tester la cohérence, la normalisation, les cas limites. Utiliser des outils de visualisation comme des diagrammes de classe ou des entités-associations permet d’identifier les zones à risque avant d’écrire une ligne de SQL.
Collaborer dès le départ.
Une bonne modélisation ne se fait pas en silo. Elle implique les développeurs, les métiers, les data engineers, les référents produit… Chacun apporte un regard complémentaire sur la donnée, ses usages, sa sensibilité, ses règles de gestion. C’est cette représentation collective qui garantit la solidité du modèle.
S’appuyer sur des outils adaptés.
Les techniques de modélisation gagnent en clarté avec de bons outils. Lucidchart, dbt, Erwin, ou même un tableau blanc en session de travail collaboratif. Le plus important, c’est de pouvoir représenter visuellement la structure, itérer facilement, et partager les modèles avec toutes les parties prenantes.
Documenter, versionner, maintenir.
Le modèle doit être lisible, traçable, et maintenable. Chaque entité, chaque règle métier, chaque dépendance doit être documentée. Il faut aussi garder une logique de version. Cela va permettre de savoir qui a modifié quoi, pourquoi, et quand. C’est ce qui permet à l’équipe de rester alignée dans la durée.
En résumé, modéliser correctement ses données, c’est combiner rigueur, vision d’ensemble et collaboration. C’est penser l’architecture d’un système d’information, étape par étape, avec méthode et anticipation.
Exemple d’une modélisation de base de données en étoile
Aller plus loin : vers une modélisation data-driven et gouvernée
Dans un environnement cloud, distribué, où cohabitent Big Data, Machine Learning, IA, IoT ou edge computing, modéliser devient un levier stratégique. Sans modélisation rigoureuse, pas de scalabilité maîtrisée, pas de qualité de données, pas d’automatisation fiable.
C’est là que la démarche data-driven prend tout son sens. Modéliser à partir des usages, c’est penser en amont qui consomme la donnée, dans quel objectif, sous quel format et à quelle fréquence. On ne se contente pas de stocker. On conçoit pour qualifier, transformer, exploiter, réutiliser. La modélisation devient un levier d’optimisation transverse.
Cette approche suppose une coordination étroite entre les architectes data, les métiers, les équipes tech, mais aussi les fonctions de sécurité et de conformité. Ensemble, ils construisent une vision partagée des objets et de leur cycle de vie. On documente, on trace, on gouverne la donnée avec méthode.
Et pour que cette gouvernance tienne dans la durée, il faut des outils. On s’appuie sur des catalogues, des référentiels, des métadonnées, des politiques d’accès et des règles de qualité. Le modèle devient un point d’ancrage, connecté à tout l’écosystème analytique, cloud ou algorithmique.
Enfin, avec l’émergence d’approches comme le Data Mesh, la modélisation évolue encore. Chaque domaine de l’entreprise prend la main sur ses propres données, les traite comme des produits, les documente, les versionne et les expose à d’autres équipes. On passe d’une modélisation centralisée à une culture distribuée.
Conclusion : modéliser, c’est concevoir intelligemment ses données
Vous l’aurez compris, modéliser est une étape stratégique, essentielle pour structurer l’information, fiabiliser les traitements, et garantir l’évolutivité des systèmes. Que ce soit pour construire une application métier, un référentiel de données ou un environnement analytique, un bon modèle de données fait toute la différence.
Mais un bon modèle ne tient pas qu’à sa logique interne. Il repose aussi sur des choix techniques cohérents, à commencer par celui de la base de données. Ce choix doit être aligné sur les besoins de l’application. Et pour garantir une performance optimale, il doit se faire en collaboration avec l’équipe d’infrastructure, qui prendra en charge la supervision, la montée en charge, la sécurité et la maintenance.
Chez Eleven Labs, on accompagne les entreprises sur toute la chaîne : du cadrage des besoins métier à la conception d’un modèle robuste, jusqu’à la mise en œuvre de la base de données la plus adaptée à votre contexte. Que vous partiez de zéro ou que vous cherchiez à faire évoluer un existant, on peut vous aider à poser les bons fondements pour vos projets data.
Besoin d’aide pour modéliser vos données ?
On peut vous aider à construire un modèle robuste, adapté
à votre système d’information et pensé pour durer.

