
Face à la croissance exponentielle des données, les entreprises doivent structurer, centraliser et maîtriser l’information. Le Data Lake s’impose comme l’une des réponses techniques les plus pertinentes à ce défi.
Concrètement, un Data Lake permet de centraliser l’ensemble des données de l’entreprise dans un espace unique. Données brutes, semi-structurées ou structurées, tout est rassemblé au même endroit pour simplifier leur exploitation. C’est ce socle qui permet ensuite de les valoriser, que ce soit pour des analyses, de la visualisation ou des projets d’intelligence artificielle.
C’est un projet structurant qui nécessite des choix techniques solides, une architecture data adaptée et une gouvernance rigoureuse. Sinon, le Data Lake devient rapidement un lac de données inutilisable.
Dans cet article, on détaille les étapes clés, les bonnes pratiques et les erreurs à éviter pour construire un Data Lake fiable, évolutif et réellement utile aux équipes.
Qu’est-ce qu’un Data Lake ?
Un Data Lake est une solution qui permet de centraliser toutes les données de l’entreprise, qu’elles soient brutes, structurées ou non. Contrairement à un entrepôt de données classique, il n’impose pas de format prédéfini. Les données y sont stockées telles quelles et organisées au fil du temps selon les besoins. C’est un espace unique qui simplifie le stockage, l’accès, le traitement et l’utilisation des données, quelle que soit leur source.
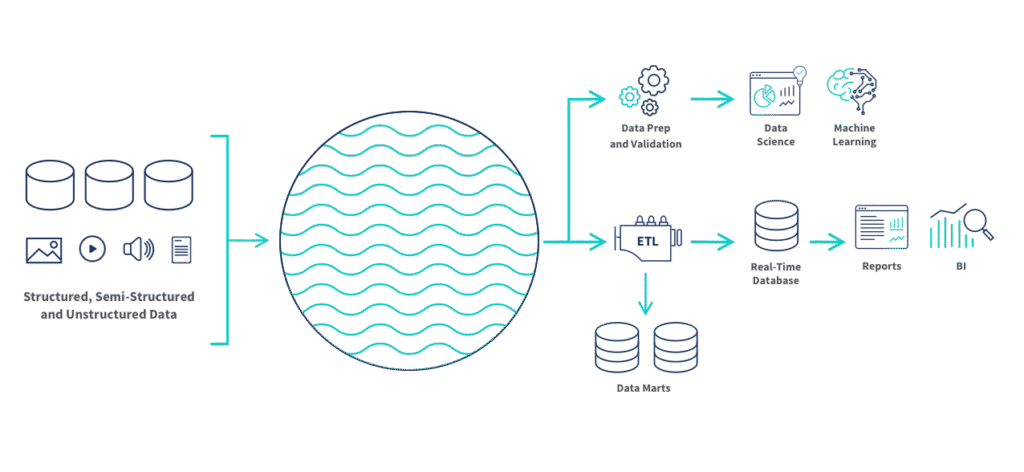
Data Lake, Data Warehouse et Data Lakehouse : lequel choisir ?
Toutes les entreprises n’ont pas les mêmes besoins en matière de stockage et d’exploitation des données. Entre Data Lake, Data Warehouse et Data Lakehouse, le choix dépend du type de données à gérer, des usages visés et du niveau de structuration attendu. Voici un comparatif simple pour choisir la bonne solution pour votre projet.
| Architecture | Forces | Limites | Cas d’usage typique |
| Data Lake | Grande capacité de stockage. Accueille des données brutes, semi-structurées ou structurées. Flexible. | Données non exploitées immédiatement sans gouvernance stricte. Complexité d’exploitation sans outils adaptés. | Centraliser toutes les données d’une entreprise pour les rendre accessibles aux équipes Data et aux Data Scientists. |
| Data Warehouse | Stockage structuré et optimisé pour l’analyse. Performant pour le reporting et la BI. | Moins flexible. Coûts plus élevés pour les gros volumes. Nécessite de transformer les données avant intégration. | Analyse décisionnelle et reporting à partir de données métier bien structurées. |
| Data Lakehouse | Combine la flexibilité du Data Lake et la performance du Data Warehouse. Approche unifiée. | Solution plus récente. Moins mature selon les technologies choisies. Demande une expertise technique solide. | Projets Data qui nécessitent à la fois du stockage brut et de l’analyse rapide, comme le Machine Learning ou l’analyse temps réel. |
Rien n’empêche de combiner plusieurs approches dans une architecture globale.
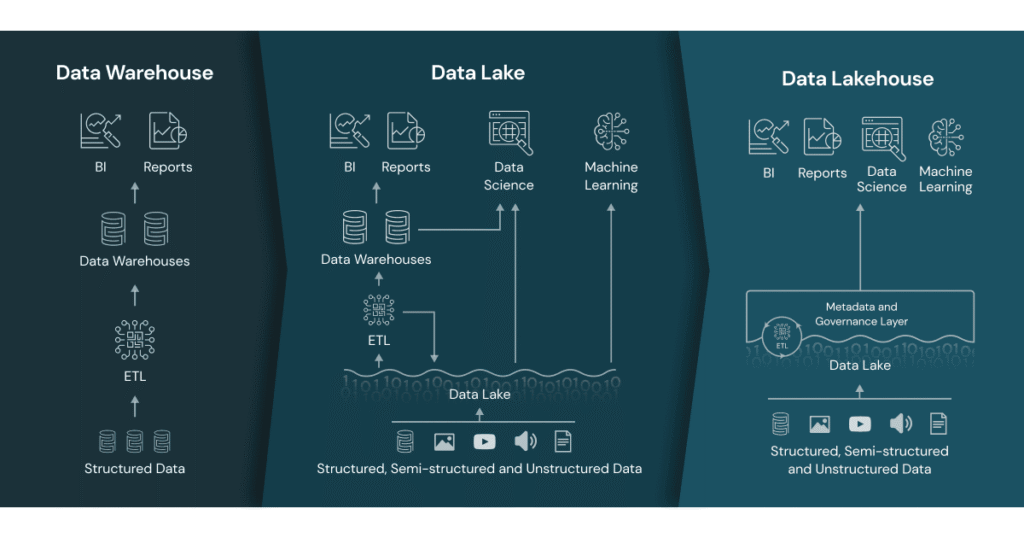
Quels sont les avantages d’un Data Lake ?
Si vous êtes encore là, c’est que grâce au comparatif ci-dessous, vous êtes convaincus que le Data Lake répond aux besoins de votre environnement. Et on vous comprend car cette approche reste aujourd’hui l’un des modèles les plus efficaces pour centraliser et valoriser les données, en s’appuyant sur les dernières tendances du big data et des architectures cloud.
Le Data Lake convient particulièrement aux entreprises confrontées à la complexité croissante des données et à la nécessité de créer un espace de stockage évolutif et performant. Sa mise en œuvre permet de simplifier l’intégration des données provenant de sources multiples, sans passer par des modèles rigides hérités du data warehousing traditionnel.
Voici les avantages concrets d’un Data Lake pour votre entreprise :
- Grande capacité de stockage adaptée aux grands volumes de données, avec un espace structuré en zones pour gérer leur cycle de vie.
- Flexibilité d’utilisation qui permet de traiter et d’exploiter tous types de données, qu’elles soient brutes, structurées ou non, selon les besoins métier et les cas d’usage.
- Accès simplifié aux données pour les équipes techniques, métiers et analystes, avec la possibilité d’intégrer des outils variés pour renforcer la gestion des données et la sécurité.
- Facilitation du traitement des données, de leur préparation jusqu’à l’analyse, en s’appuyant sur des architectures modernes comme Databricks.
- Évolutivité qui permet de faire évoluer la plateforme au fur et à mesure, en fonction de la croissance des besoins et des projets, qu’il s’agisse de reporting, de machine learning ou d’intelligence artificielle.
Les bonnes pratiques et pièges à éviter avant de se lancer
Avant de se lancer dans la construction de votre plateforme data, les bons fondamentaux doivent être posés dès le départ. Les erreurs classiques entraînent souvent une mauvaise qualité des données, des coûts inutiles ou un lac de données inutilisable. Voici les points clés à garder en tête pour éviter ces risques.
Commencer par les cas d’usage et les besoins, pas par la techno
Le Data Lake n’est pas une solution magique. Avant de choisir les outils, il faut identifier les vrais besoins métiers et les usages concrets attendus. C’est ce qui conditionne la réussite du projet.
Ne pas sous-estimer la gouvernance et la qualité des données
Sans gouvernance claire, la qualité des données se dégrade rapidement. Mauvaise gestion des accès, données dupliquées, formats incohérents… Ces problèmes freinent l’exploitation et augmentent la complexité.
Impliquer les métiers dès le début
Le Data Lake concerne autant les équipes techniques que les métiers. Si les utilisateurs ne sont pas associés dès la phase de cadrage, on prend le risque de construire une solution déconnectée des besoins terrain.
Éviter l’effet “Data Swamp”
Un Data Lake mal piloté se transforme vite en marécage de données inutilisables. Sans structuration progressive et sans contrôle, le projet devient ingérable.
Avancer par étapes
On ne construit pas un Data Lake en une seule fois. Démarrer par un MVP, tester, ajuster… Cette approche limite les risques et permet de maîtriser la complexité au fil du temps.
Les 8 étapes pour mettre en place un Data Lake en entreprise
On y est, c’est parti pour créer votre plateforme data, pas à pas. On a recensé pour vous 8 étapes à suivre afin de créer une solution performante, sécurisée et durable. Chaque étape a un rôle clé pour limiter les risques et assurer la pérennité de la plateforme. Allons-y :
Étape 1 – Évaluer les besoins métiers et data
Avant toute décision technique, il faut cadrer le projet. L’évaluation des besoins commence par une cartographie des données existantes et donc une série de questions auxquelles répondre :
- Où se trouvent vos données ?
- Quels types de données possédez-vous ?
- Qu’arrive-t-il à vos données ?
- Vos données sont-elles exactes et sûres ?
- Comment exploiterez-vous vos données dans le futur ?
On identifie les utilisateurs, leurs usages, les irritants (accès limités, données dispersées, redondances) et les objectifs métiers visés. Ce diagnostic permet aussi de mesurer la maturité data de l’entreprise et de poser les bases d’une gouvernance adaptée.
Étape 2 – Concevoir l’architecture technique
L’architecture du Data Lake doit répondre aux exigences de scalabilité, de performance et de sécurité. Cloud public, privé ou hybride, choix des technologies et organisation logique du stockage (zones brutes, nettoyées, valorisées) doivent être définis dès le départ. Cette structuration facilite la gestion du cycle de vie des données, du stockage initial jusqu’au traitement et à l’exploitation finale. On privilégie une approche modulaire et évolutive, avec des itérations pour sécuriser chaque phase.
Étape 3 – Sélectionner les technologies adaptées
Le choix des technologies conditionne la performance et la pérennité du Data Lake. Deux solutions s’imposent aujourd’hui.
Databricks, basé sur Apache Spark, est conçu pour gérer de grands volumes de données et des traitements distribués à grande échelle. Il s’appuie sur les stockages cloud comme Amazon S3 ou Azure Data Lake Storage et combine les avantages du Data Lake et du Data Warehouse via son approche Lakehouse. Ils ont d’ailleurs créé le format Delta Lake pour les fondations d’une architecture de type Lakehouse. C’est le choix technique privilégié pour les projets complexes ou les besoins avancés en machine learning.
Snowflake, de son côté, simplifie le stockage et l’analyse des données structurées et semi-structurées. Sa capacité à s’intégrer nativement dans les architectures Data Lake et son modèle sans gestion d’infrastructure en font une option efficace pour les usages analytiques et métiers.
Ces deux solutions sont aujourd’hui complémentaires dans la plupart des architectures Data Lake modernes.
Étape 4 – Collecter et ingérer les données
On définit les pipelines d’intégration pour collecter les données brutes depuis les sources internes ou externes, en garantissant leur traçabilité et leur qualité. Nettoyage, validation, préparation des données… ces étapes sont essentielles pour limiter la propagation d’erreurs ou de données de mauvaise qualité. La gouvernance des données doit être opérationnelle dès cette phase pour assurer la cohérence et la fiabilité du lac de données.
Étape 5 – Stocker et organiser les données
Pour que les données restent exploitables et maîtrisées, il est essentiel de les organiser de manière structurée et évolutive. Une bonne pratique largement éprouvée consiste à mettre en place un système de zoning, qui permet d’isoler les données en fonction de leur niveau de transformation, de qualité et de maturité. Cette approche facilite la gestion du cycle de vie des données et renforce la sécurité.
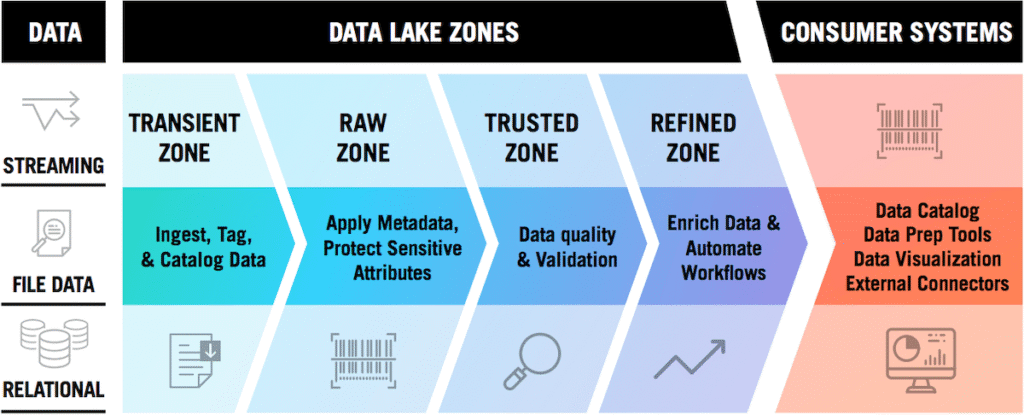
On distingue généralement plusieurs zones complémentaires :
- Zone Rawdata : les données brutes, collectées telles quelles depuis les sources, sans modification. C’est la copie d’origine, utile pour les contrôles et les traitements ultérieurs.
- Zone Trusted : les données validées et nettoyées, sur lesquelles les équipes peuvent s’appuyer en toute confiance pour des usages opérationnels.
- Zone Refined : les données enrichies et consolidées, prêtes à être utilisées dans des analyses avancées, du reporting ou des projets de data science.
- Zone Sandbox : un espace isolé dédié aux expérimentations et aux tests, qui permet de manipuler les données sans impacter le reste du système.
Ce zonage permet d’appliquer des règles de sécurité, d’accès et de cycle de vie spécifiques à chaque type de donnée. On limite ainsi les risques liés à la complexité, à la qualité des données ou à leur usage non maîtrisé.
Étape 6 – Gérer les accès et la sécurité
La gestion des accès doit être fine et basée sur le principe du moindre privilège. On définit une matrice de droits, on met en place des mécanismes d’authentification renforcée, du chiffrement, de la journalisation des accès et des contrôles réguliers. La sécurité ne se limite pas aux aspects techniques, elle s’intègre dans la gouvernance globale des données.
Étape 7 – Gouverner le cycle de vie des données
On définit des règles claires d’archivage, de purge et de conservation. La qualité des données est contrôlée en continu pour éviter que le Data Lake ne se transforme en Data Swamp. Cette gouvernance permet de préserver les performances, d’optimiser les coûts de stockage et de maintenir la valeur des données dans la durée.
Étape 8 – Exploiter et valoriser les données
On connecte le Data Lake aux outils d’analyse, de reporting, de data science ou d’intelligence artificielle. Les données sont rendues accessibles aux équipes techniques et métiers, en respectant les règles de sécurité et de gouvernance. C’est cette dernière étape qui transforme l’infrastructure en véritable levier de performance et d’innovation.
Le cloud au cœur du Data Lake
Aujourd’hui, la majorité des Data Lakes s’appuient sur le cloud. Cette approche offre une flexibilité essentielle pour gérer la volumétrie croissante des données et adapter l’infrastructure en fonction des besoins.
Les plateformes cloud permettent d’ajuster les capacités de stockage et de traitement à la volée, sans avoir à investir dans des serveurs physiques. Les grands fournisseurs comme AWS, Microsoft Azure ou Google Cloud proposent des services managés qui simplifient le déploiement, la sécurisation et l’administration des Data Lakes.
Les compétences clés nécessaires pour la mise en place et la gestion d’un Data Lake ?
La mise en place d’un Data Lake mobilise des profils complémentaires. Il faut des architectes pour concevoir une infrastructure Data et Cloud fiable et évolutive. Les Data Engineers assurent l’ingestion, l’organisation et le traitement des données. Des experts sécurité et gouvernance garantissent la protection des données et la maîtrise des accès. Enfin, l’accompagnement des équipes métiers est essentiel pour que la plateforme réponde aux usages concrets et devienne un véritable levier de valeur.
Conclusion : réussir la mise en place d’un Data Lake passe par une approche progressive et gouvernée
La mise en place d’un Data Lake est un projet structurant qui demande méthode, expertise et rigueur. Sans cadrage, sans gouvernance et sans accompagnement, le risque de complexité et de dérive est réel.
Pour sécuriser le projet, il faut avancer par étapes, impliquer les métiers, structurer l’architecture et s’appuyer sur des experts Data et Cloud. C’est cette approche progressive et gouvernée qui permet de transformer un Data Lake en véritable levier d’innovation et de performance. À condition de le concevoir comme un produit à part entière, capable d’évoluer avec les besoins des équipes et les contraintes de l’entreprise.
Chez Eleven Labs, nos experts Data vous accompagnent dans la construction de votre Data Lake.
Besoin d’aide pour construire votre Data Lake ?
On peut vous aider à construire une plateforme robuste, adaptée à
votre système d’information et pensé pour durer.


