
Déploiement d’un agent IA d’automatisation des CV et d’un chatbot IA interne de recherche de profils

Eleven Labs est un agence de conseil et d’ingénierie web & IA spécialisée en développement web, architecture logicielle, DevOps et Intelligence Artificielle. En parallèle des missions clients, l’entreprise mène des travaux de R&D internes afin d’industrialiser des cas d’usage IA concrets, avec une approche orientée architecture, maîtrise des coûts, sécurité et exploitabilité long terme.
OpenAI GPT-4o, Mistral, API Nest.js,
ORM (Drizzle), React Query, Next.js,
React, spécification OpenAPI, authentification Google, GCP, Cloud Run, Cloud SQL (PostgreSQL).

Lead Développeur JS / IA

Développeur Fullstack IA

Développeur Fullstack IA

Senior DevOps
Le contexte du projet d’automatisation des compétences et de recherche intelligente de profils
Au sein des équipes commerciales et RH, une opportunité d’automatisation et de structuration des compétences internes a été identifiée.
Les informations existaient déjà — expériences, technologies, contextes sectoriels, réalisations — mais elles étaient réparties entre différents outils, supports et formats. Cette dispersion rendait difficile une vision consolidée des expertises internes, compliquait les analyses RH et ralentissait la préparation de supports commerciaux cohérents.
Le premier objectif a donc été de concevoir un outil interne centralisé, accessible à tous, adossé à une base de données structurée. Cet outil agrège l’ensemble des profils, des missions et des compétences afin d’en proposer une vue d’ensemble claire et exploitable. Il permet une lecture transverse des expertises disponibles, facilite la représentation cohérente des consultants et supporte différentes analyses RH et commerciales grâce à des indicateurs et visualisations synthétiques. Les informations issues des missions sont consolidées et présentées de manière structurée dans des rapports RH, des dossiers de compétences ou des REX mission, avec un niveau de formatage homogène et maîtrisé.
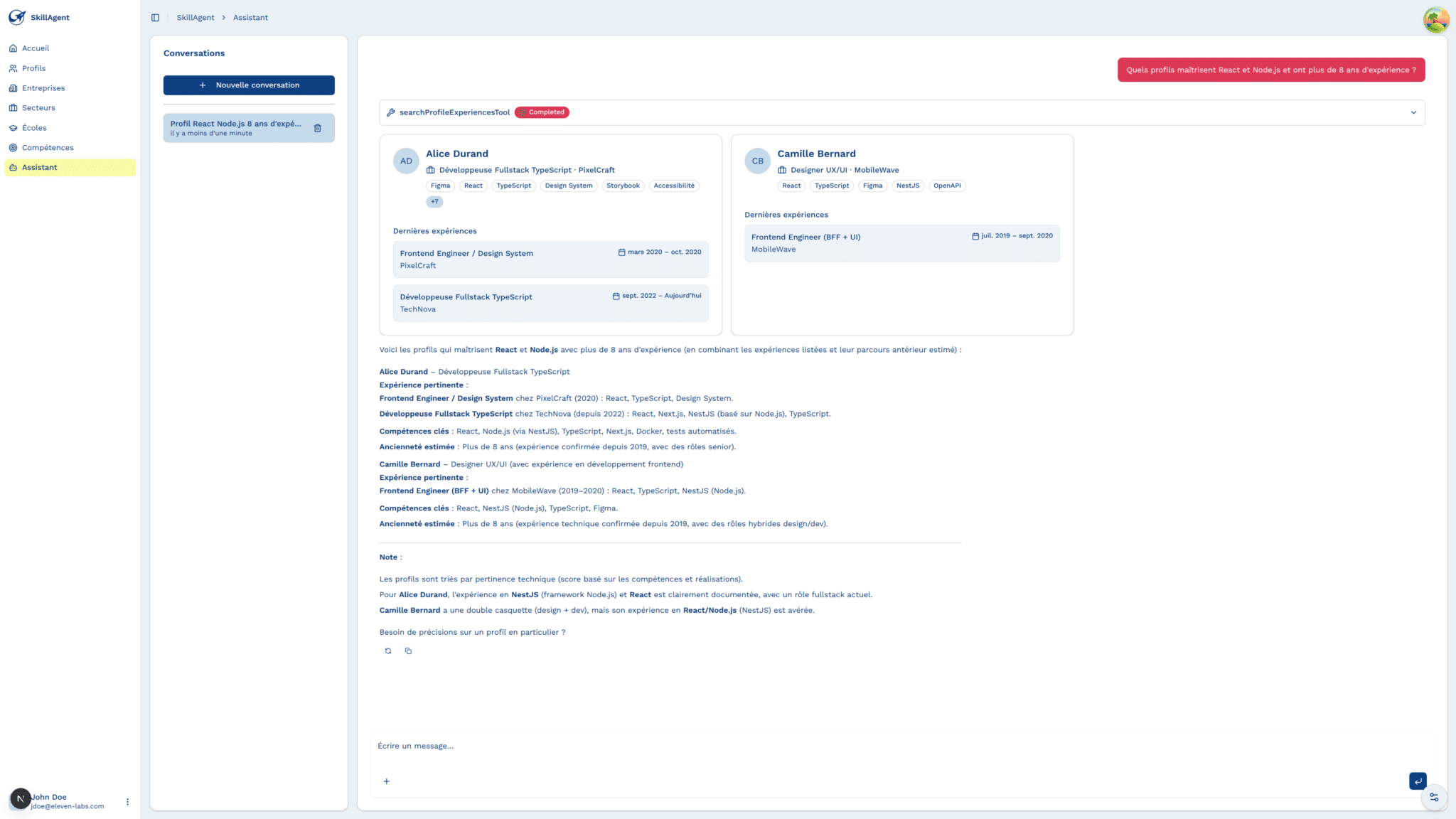
Une fois ce socle structuré et accessible mis en place, une suite logique s’est imposée. Si la donnée est centralisée, modélisée et interrogeable, elle peut être exploitée via une recherche intelligente.
C’est dans cette continuité qu’un chatbot IA interne a été développé. Connecté à l’outil comme source de vérité, il permet d’exprimer un besoin en langage naturel — expérience, technologies, contexte projet, secteur, type de mission — et d’obtenir rapidement une shortlist pertinente.
Le projet est donc passé d’un besoin documentaire à la construction d’un véritable outil interne combinant socle data structuré et assistant de recherche intelligent, avec une expérience plus proche d’une application métier que d’un simple chatbot IA conversationnel.
Les enjeux techniques liés à l’industrialisation d’un agent IA interne
Le projet a vite dépassé le simple cadre fonctionnel. Une fois l’agent IA et le chatbot conçus, il fallait les intégrer proprement dans l’existant, avec une approche robuste côté données, recherche et exécution des workflows.
Le premier gros sujet a été la recherche et le matching de profils. L’objectif était simple sur le papier, à partir d’un extrait d’appel d’offres, identifier les profils les plus cohérents. En pratique, le problème est plus fin. On a séparé le matching en deux dimensions, les hard skills, c’est-à-dire les compétences et technologies attendues, et le contexte des missions, plus proche des soft skills et de l’expérience réelle.
Plusieurs pistes ont été explorées. On a testé des approches proches du RAG avec embeddings, en vectorisant les compétences extraites des profils et celles issues des appels d’offres pour comparer les similarités. On a aussi expérimenté une vectorisation plus globale, en travaillant sur la synthèse d’un appel d’offres et sur la vectorisation fine de chaque expérience d’un profil. L’idée était de combiner ces signaux, puis éventuellement de reranker les profils les plus proches.
En parallèle, on a poussé la recherche full-text PostgreSQL assez loin. Une vue matérialisée a été construite pour agréger les expériences et appliquer des poids différents selon les colonnes. Les compétences, le contexte, les réalisations ou encore le poste occupé ne portent pas le même signal. Le scoring a été ajusté progressivement pour éviter les faux positifs, notamment quand l’utilisateur saisit beaucoup de mots-clés. Plus la requête est dense, plus le ranking devient sensible à la pondération.
Un autre défi important a concerné le choix du modèle pour l’extraction de données structurées. Extraire proprement des expériences, des compétences et des contextes à partir d’un CV hétérogène n’est pas trivial. Tous les modèles ne se valent pas sur ce type de tâche. On a donc mis en place un benchmark interne avec un Google Sheet dédié pour comparer les performances des différents modèles. En parallèle, un outil de test interne a été développé pour exécuter les mêmes prompts sur plusieurs modèles et mesurer la qualité, la cohérence des sorties et la stabilité dans le temps. Ce travail de comparaison a permis de sélectionner les modèles les plus adaptés à la structuration, en tenant compte à la fois de la qualité des résultats, de la latence et des coûts.
Enfin, l’orchestration via Mastra a demandé de l’adaptation. La librairie était encore en beta au démarrage et évoluait régulièrement. Les mises à jour fréquentes impliquaient des ajustements côté code pour maintenir la stabilité du système et éviter les régressions.
Ces défis relèvent moins de l’IA en tant que telle que de son intégration dans un système réel. Dès qu’on parle d’agent connecté à une base interne RH, de recherche structurée et d’infrastructure sécurisée, on est sur un sujet d’architecture IA et de robustesse, pas uniquement de modèle.
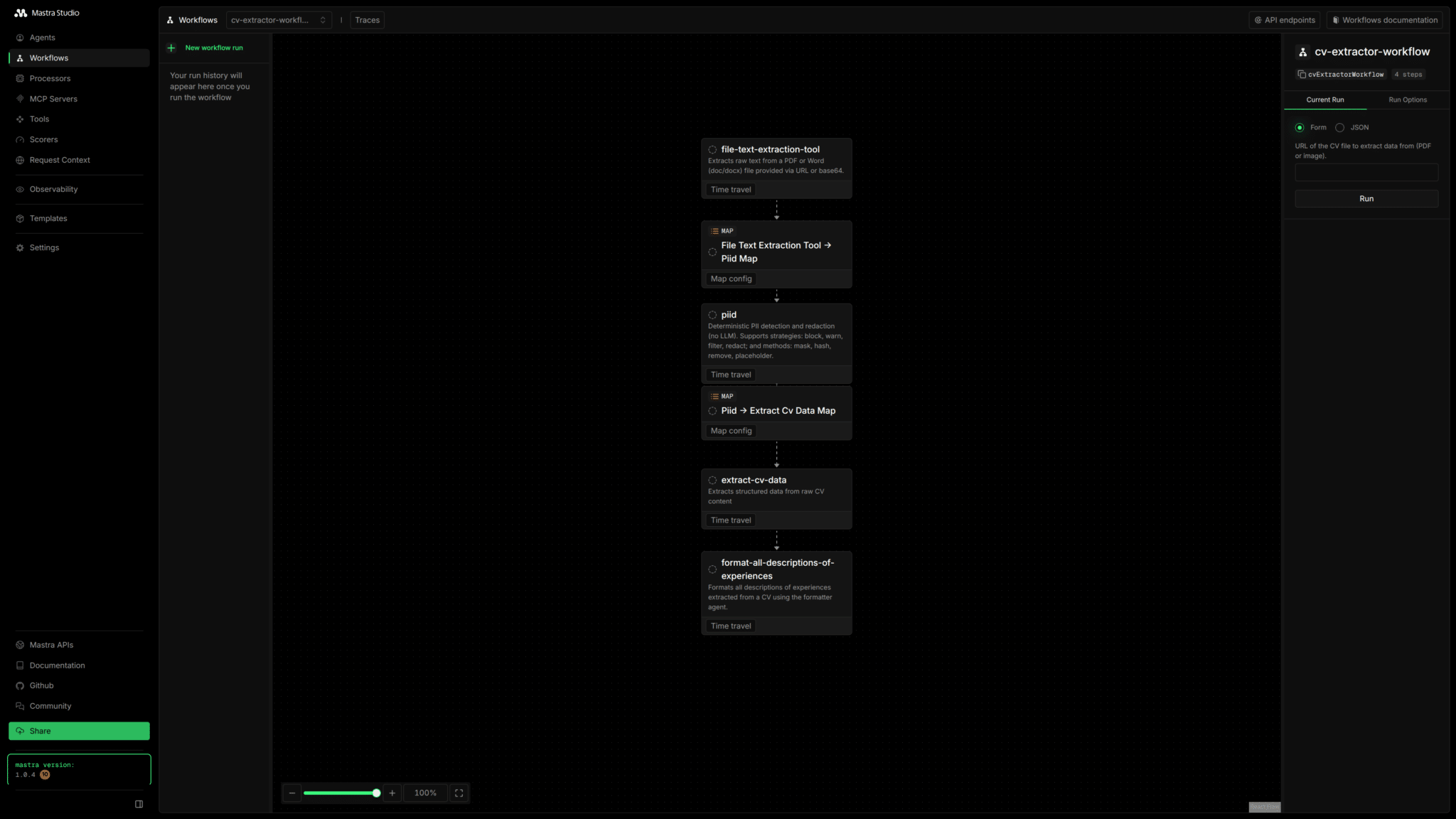
“ Ce qui compte, c’est le workflow. On extrait le texte du CV, on nettoie les données sensibles, on structure avec le modèle, on enregistre en base, puis on fait la recherche full-text avec un scoring qu’on ajuste. Si une étape est mal pensée, le reste devient vite incohérent. Toute la complexité est là, dans l’enchaînement propre des briques. ”
Les missions réalisées pour construire et déployer les agents IA interne
Structuration et industrialisation de la donnée consultant
- Conception d’une base centralisée de profils consultants modélisée pour être interrogeable et exploitable par des agents IA.
- Développement d’un pipeline d’ingestion documentaire intégrant une extraction texte via OCR dédié pour garantir la complétude des contenus.
- Mise en place d’une étape d’anonymisation des données sensibles avant appel aux modèles de langage.
- Structuration des informations via GPT-4o afin d’extraire expériences, compétences, formations et missions dans un format normalisé.
- Reformattage des descriptions en HTML pour standardiser les sections contexte, tâches et réalisations.
- Enregistrement des données structurées en base Cloud SQL PostgreSQL.
- Développement d’un générateur documentaire capable de produire automatiquement des CV en PDF et PPTX à partir des données consolidées.
Conception et orchestration des agents IA
- Orchestration complète des workflows IA via Mastra afin de rendre le système testable, observable et maintenable.
- Développement d’un agent IA documentaire pilotant les différentes étapes du pipeline de traitement des CV.
- Conception d’un chatbot IA interne déclenchant dynamiquement des tools selon l’intention utilisateur.
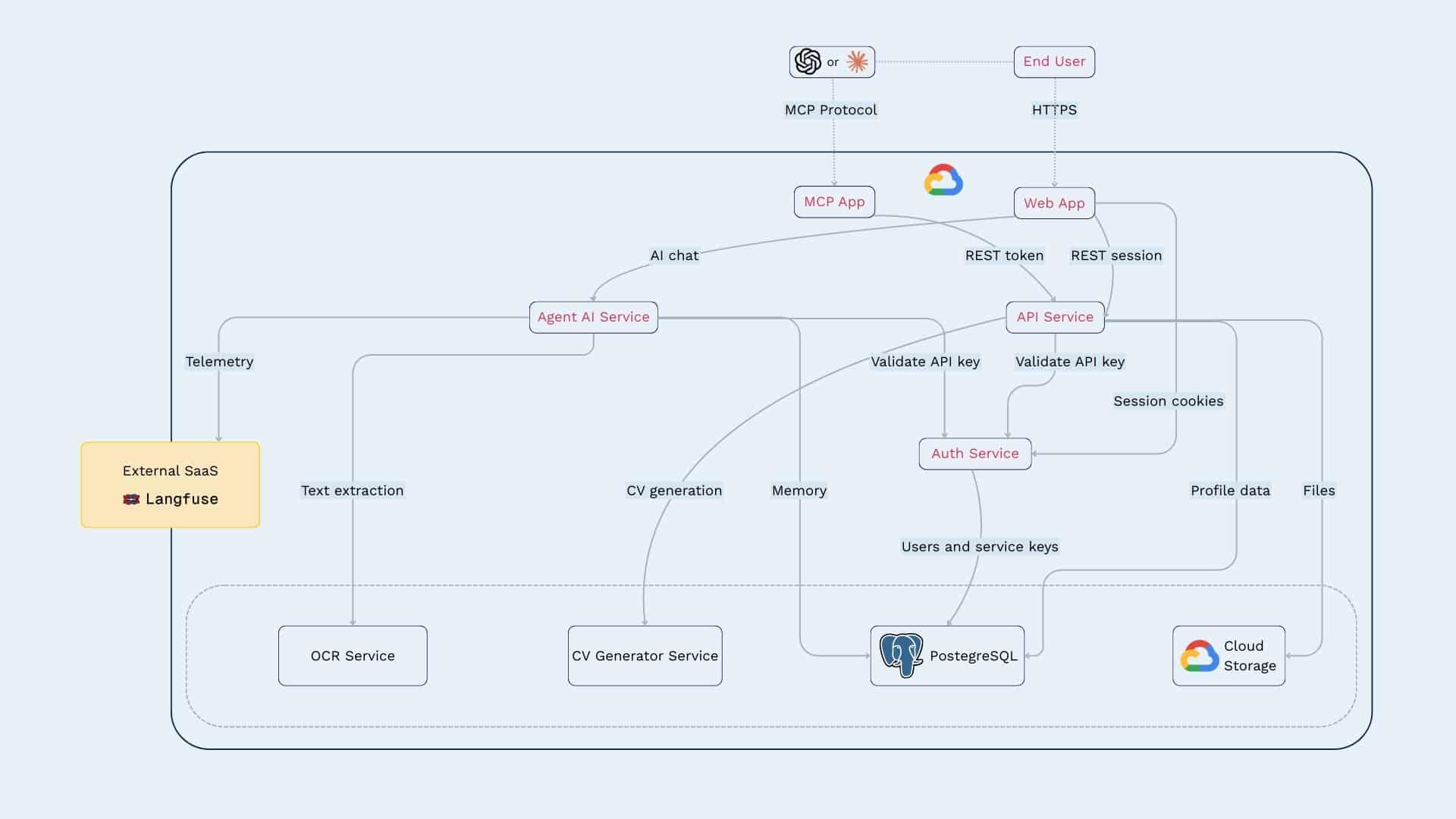
- Développement d’un serveur MCP exposant des outils métiers sécurisés connectés à la base interne.
- Implémentation de mécanismes de routing multi-modèles via OpenRouter pour optimiser coût, latence et qualité de réponse.
Moteur de recherche et pertinence du matching
- Implémentation d’une recherche full-text native PostgreSQL adaptée aux besoins internes.
- Création d’une vue matérialisée pour optimiser les performances de recherche et le scoring.
- Ajustement du scoring afin d’améliorer la pertinence des résultats multi-critères.
- Développement de tools distincts pour la recherche par compétences/expériences et par identité consultant.
Expérience utilisateur et intégration conversationnelle
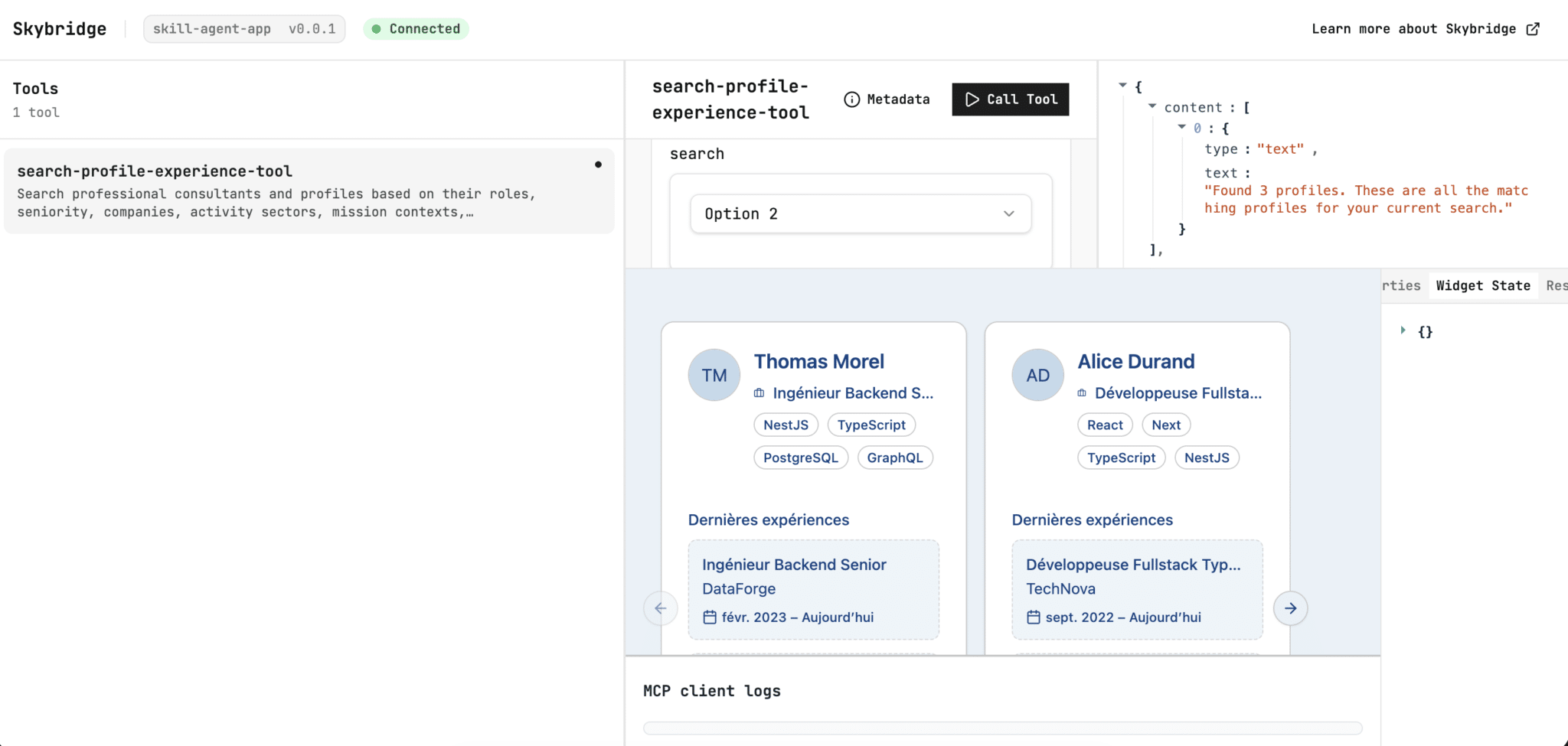
- Intégration d’une UI conversationnelle enrichie via Skybridge (SDK open source).
- Affichage dynamique d’un carrousel de profils directement dans le fil de discussion ChatGPT ou Claude.
- Connexion sécurisée entre l’interface conversationnelle et le serveur MCP hébergé sur GCP.
- Déploiement de l’application sur Cloud Run avec authentification Google et gestion des environnements.
- Mise en place de l’observabilité via Langfuse pour tracer les interactions agent et faciliter l’amélioration continue.
Les livrables et résultats obtenus grâce à la mise en place des agents IA interne
Résultats
Les impacts observés sont principalement opérationnels et organisationnels :
Réduction estimée de 60 à 70 %
Réduction estimée de 50%
Accélération significative du time-to-response
Renforcement de la capacité d’analyse RH
Livrables
- Un agent IA documentaire opérationnel capable de transformer des CV hétérogènes en données structurées exploitables.
- Un chatbot IA interne connecté via serveur MCP à des outils métiers sécurisés.
- Une application ChatGPT et application Claude connectées à un serveur MCP interne, intégrant une MCP UI via le SDK open source Skybridge permettant l’affichage dynamique de composants interactifs directement dans le fil de discussion.
Découvrez nos cas clients similaires


